

Software, Sagan, and Human Civilization
Software, Sagan, and Human Civilization
Has big data delivered on its promises?
I am generally unabashedly optimistic about software. I feel blessed to live in an era where I can get paid to solve logic problems all day and feel like I’m on the cutting edge of technological progress. Sometimes, though, in my darkest moments of self-doubt, I get the feeling that maybe all the millions of people and trillions of dollars that are pouring into the software industry would be better spent somewhere else. Is this titanic effort to improve how we shuffle bits around really benefiting humanity?
I promise I’ll get back to this question, but first: a short parable about two astronomers and their quest to classify extraterrestrial civilizations.
Back in 1964, the Soviet astronomer Nikolai Kardashev wrote a paper entitled “Transmission of Information by Extraterrestrial Civilizations.” In the paper, he proposed a novel method for measuring a civilization’s technological achievement. The Kardashev scale, as it has come to be known, characterizes civilizations based on their energy consumption:
Type Ⅰ: Technological level close to the level presently attained on earth, with energy consumption at ≈4×1019 erg/sec.
Type Ⅱ: A civilization capable of harnessing the energy radiated by its own star (for example, the stage of successful construction of a Dyson sphere), with energy consumption at ≈4×1033 erg/sec.
Type Ⅲ: A civilization in possession of energy on the scale of its own galaxy, with energy consumption at ≈4×1044 erg/sec.
Kardashev’s scale failed to help him detect alien life, but it became popular among scientists and science-fiction enthusiasts alike. In his 1973 book Cosmic Connection, astronomer Carl Sagan proposed a formula for more precisely calculating a civilization’s position on the Kardashev scale:

where P is the civilization’s total available power in Watts. In 1973, humanity consumed about 8.63 Terawatts of energy and thus represented a type 0.7 civilization.
Sagan wasn’t satisfied with this level of specificity. He proposed a second axis of measurement:
But there may be more significant ways to characterize civilizations than by the energy they use for communications purposes. An important criterion of a civilization is the total amount of information that it stores. This information can be described in terms of bits, the number of yes-no statements concerning itself and the universe that such a civilization knows.
If we have used numbers to describe energy, we should perhaps use letters to describe information. There are twenty-six letters in the English alphabet. If each corresponds to a factor of ten in the number of bits, there is the possibility of characterizing with the English alphabet a range of information contents over a factor of 10^26–a very large range, which seems adequate for our purposes.
Sagan used letters, but for ease of graphical representation I will refer to levels on the Sagan scale by their numerical equivalent. Sagan proposed that Level 1 (or A) would correspond to a civilization that knows 10^6 bits of information, with each successive level representing a 10-fold increase in the number of bits. According to Sagan’s estimation, humanity in 1973 had at most 10^13 bits of information in books; making allowances for oral tradition and graphics/photography/art, he puts human civilization in the ballpark of 10^14 total bits, corresponding to level 8 on his scale.
In 1973, these two scales were more or less in agreement. In both, humanity was ranked at about a third of the possible score. They are both logarithmic scales, so we might expect to seen similar trends, and indeed we do—under the reasonable assumption that human civilization in 1800 had total information on the same order of magnitude as Sagan’s estimate for just books in 1973 (that is, level 7 on the Sagan scale), both measurements also have a very similar slight upward trajectory from the beginning of the 19th century:

Energy Source: Our World in Data
Looking at this chart, one gets the sense that humanity’s position on the Kardashev and Sagan scales is likely to remain highly correlated. The next fifty years proved this prediction very, very wrong.
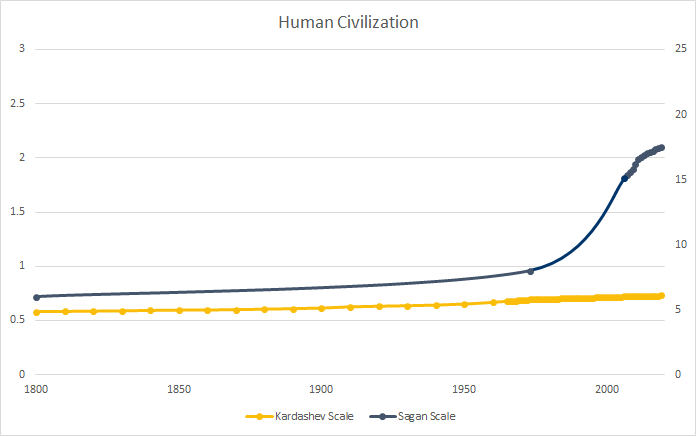
Energy Source: Our World in Data, Information Source: Statista
We can quibble about the exact numbers here—the Statista data I’m using to calculate the Sagan scale seems to include copies of duplicate information, so it may overstate human knowledge by an order of magnitude or two—but it seems clear that there has been a major decoupling. Human energy consumption has continued to increase at a steady exponential rate, which shows up as roughly linear on the logarithmic Kardashev scale. Our information volume has grown much, much faster than that. From 1800 to 1973, both energy consumption and information increased by roughly a factor of 10. Since 1973, energy use has increased by a factor of 2.3. For information, that number is somewhere in the ballpark of 3,280,000,000.
The difference between these two metrics is likely to expand. According to Our World in Data, energy consumption is falling across Europe and North America. If energy use in the developing world reaches this threshold and stalls, we may actually see a decline in humankind’s position on the Kardashev scale. Information growth, on the other hand, is expected to accelerate.
If these two scales are giving us such different pictures of human technological progress, surely one must be better than the other. Which is it?
This is a very squishy question to address, but I’m going to try to do so by looking at concrete metrics that I think most people care about. I picked agricultural yields and life expectancy, because it was easy to find historical data. Here’s global energy consumption charted alongside both of these metrics:
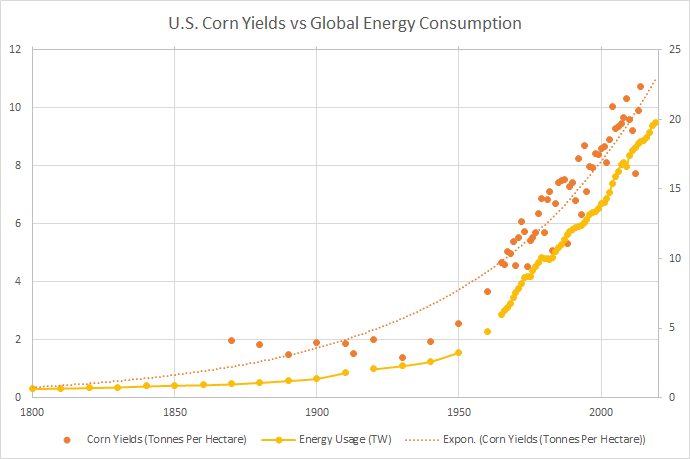
Energy Source: Our World in Data, Agriculture Source: Our World in Data
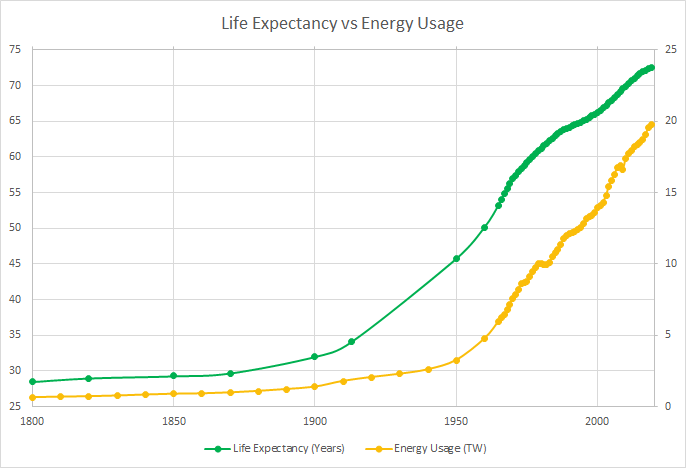
Energy Source: Our World in Data, Life Expectancy Source: Our World in Data
Energy usage seems to predict both crop yields and life expectancy pretty well. All three trends experience a clear inflection point sometime in the early 1900s.
What about information volume?
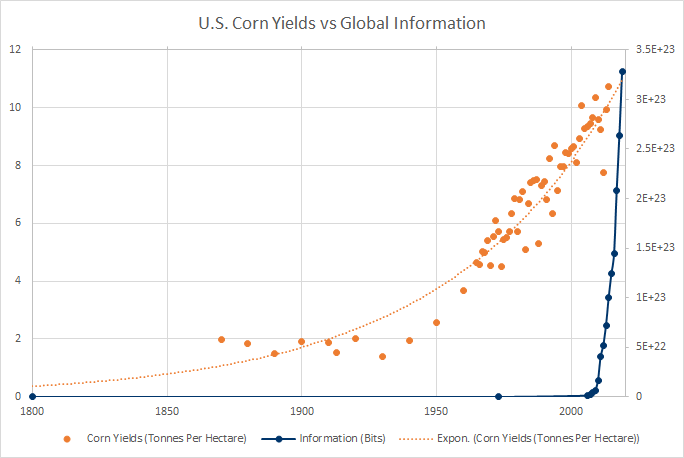
Information Source: Statista, Agriculture Source: Our World in Data
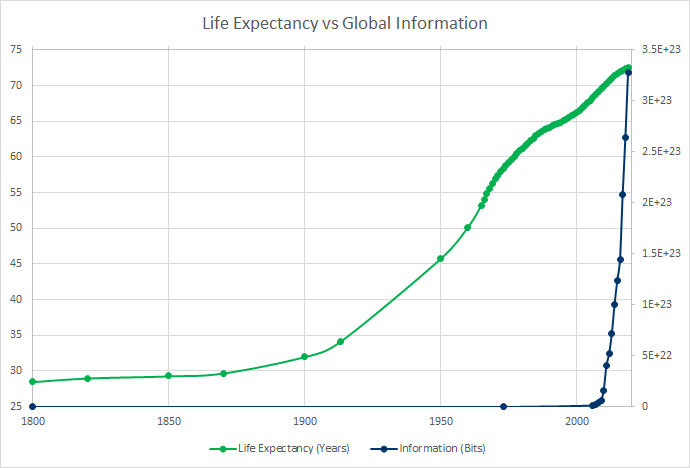
Information Source: Statista, Life Expectancy Source: Our World in Data
These trends do not match up nearly as well. In particular, the inflection point for information seems to occur at a time when life expectancy growth is actually slowing down.
My arbitrarily selected graphs don’t definitively prove anything on their own, but let’s indulge in a pessimistic interpretation. It seems like a lot of the hard and fast measures of our technological achievement match up really well with the Kardashev scale: they took off after the second industrial revolution, experienced steady exponential growth throughout the 20th century, and are now beginning to attenuate in the developed world. Our position on the Sagan scale, on the other hand, exploded at a time when our progress in the physical world was steady, or even slowing down. Humanity’s meteoric rise in recorded data doesn’t seem to have been accompanied by an associated spike in material gains.
If this is true, it doesn’t look very good for the software industry. Many of the greatest modern tech companies—think Google, Facebook, Netflix—are concerned almost solely with the production, storage, and distribution of information. At this, they have been wildly successful. Over the internet, we can almost instantaneously stream millions of ultra-HD videos, or hear thousands of viewpoints on a breaking news story. Google alone has played a huge role in humanity’s progress on the Sagan scale. The last time the company released internal statistics, in 2008, it was processing over 20,000 terabytes of data a day.
And yet… what is all this data getting us? If it's really the Kardashev scale we should be worrying about, does the information explosion even matter? According to the Bureau of Labor Statistics, the U.S. now has more than ten times as many software developers as it does physical scientists. Should I quit programming and start trying to invent a cold fusion reactor or something?
I don’t have an easy answer to these questions. That being said, I think there are a couple of reasons to be hopeful.
One reason for hope is the artificial intelligence boom. A lot of the foundational concepts in A.I. have been around since the 20th century, but it is only in the last five or six years that we have attained the critical mass of data and computing power required to get really good results with large neural networks. Maybe all this recorded information isn’t doing us much good because we don’t have the capacity to process it. A.I. might be the key to unlocking real world insights from our data.
As an example, take my smartwatch. It records a ton of information about me: where I go, how much I move, how much I sleep, what my heart rate is. This is way more personal data than anyone had access to ten years ago, but I can’t say it improves my life all that much. Sometimes I look at my step count out of idle curiosity, but that’s about it. If we could train an A.I. to detect early signs of cancer from biomedical data, however, this information might just save my life.
A more extreme example: it’s quite possible that the key to cold fusion or doubled crop yields or an end to aging is already out there, scattered like needles in the haystack of humanity’s 40 zettabytes of digital storage. If we let a sufficiently powerful text and image processing engine loose on the internet, who knows what kind of insights it might present to researchers. Maybe the combination of an obscure Ukrainian research paper, some Hindi Facebook comments, and a Chinese electron microscope image will pave the way for the next scientific revolution.
Another reason for hope is the fact that the data explosion is still quite young. We only crossed the zettabyte threshold in 2010. Institutions will take time to adapt; a 2016 OECD survey found that 15% of U.S. workers had no computer experience and close to 50% were not proficient in computer use. We may well have to wait for the maturity of the first internet-native generation to see an information-powered spike in real-world productivity.
My final and most speculative point is that it may not really matter if the information revolution pays off in “real-world” terms. The pandemic has already seen a major increase in how much of people’s lives are conducted online. In a world where Neuralink and virtual reality allow us to live as our online avatars, it may well be that software is an end in and of itself. In the most extreme case, where we manage to digitize human consciousness, we might explore the cosmos as data. That future would see the Sagan scale triumphant and my graphs about corn yields and life expectancy reduced to an anachronistic footnote.
All told, I am optimistic enough about the future of software to happily ride the ever-expanding information curve. The possible disconnect between the data explosion and physical progress isn’t nearly enough to convince me to put down my laptop, but I’m sure the thought will continue to visit me every now and then in the dead of night.
This is an interesting counter to (or maybe it's actually illustrative of) Thiel & Cowen's stagnation hypothesis - that innovation has started to move sideways since the 70s except for, of course, the world of computing and communications.
I have a tech bias as well. That there are 10x more software devs than physical scientists is an interesting fact - I don't know how to feel about it. It makes sense that that's the case, because the demand for software labor has driven the price of it up significantly. All of the low-hanging physical-science fruits have been plucked, and it's hard to make an economic case for more physical scientists. If it's true that the 21st century paradigm-shifting innovations are going to be discovered in fields like physics, this is a huge mistake on the part of the market. But if the fruits of the computing revolution are just lagging behind, then this is a good thing.
Again, I have a tech bias. I think we're seeing the beginning of a high-impact cross-disciplinary ML revolution coming to fruition in things like AlphaFold 2, GPT-3, Neuralink. On the other hand, I have no clue what's going on in the world of physics.
Nice post!